




Soooo. Following on from Part 1
So we have some job data objects coming back. Now we want to send them to the DB.
We need to add some packages. Mongoose to help us with Mongo in Node, Dotenv to get our environment variables and Nodemailer to send emails using Node of course.
npm i mongoose
npm i dotenv
npm i nodemailer
Creating the DB and writing the data
So hopefully you already have a MongoDB account and know how this goes but if not go to https://account.mongodb.com/account/login or if you want to make a loacl one you can follow along here https://flaviocopes.com/puppeteer-scraping/. Flavio has a great example already showing how this is done.
We're going to create a real-life cloud database and send our data over the wire.
So create your account, create a new project, choose the free tier
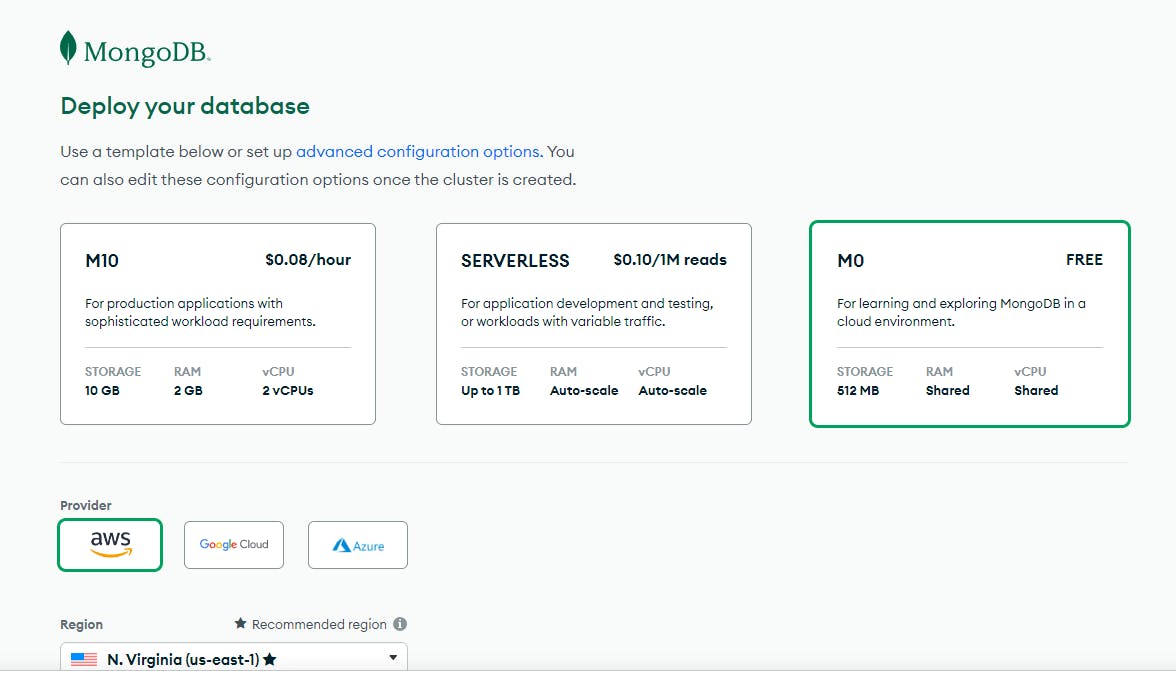
click the create button - then create your user and add your local IP to the white list.
Once everything is ok, you can build the DB, and once built click the connect button

Now you should see the Drivers tab - Click that and get your connection string
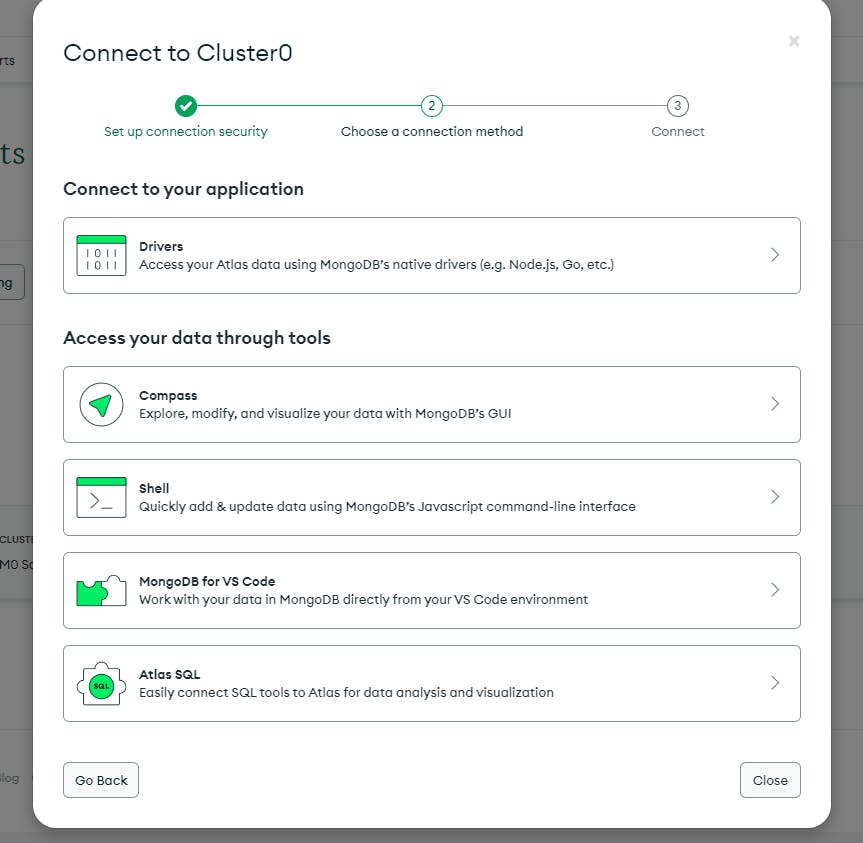
Just follow the instructions, and save the connection string.
Go to your project, create a file in the root then name it ".env". This is where we will store the connection string. If you aren't deploying this then maybe you don't need to bother doing this - you could just hardcode it inline... it's up to you really. Also, remember if you are going to push code like this to GitHub you need to add a git ignore file and add .env to it.
MONGO_URI= // the connection string from above, no space after the =
Now we model the data.
Create a folder called Models and a file called Job.js
I think that a single job should look like this.
// import the package
import mongoose from "mongoose";
// define our job model
let jobSchema = new mongoose.Schema({
title: String,
company: String,
// deatils is for the short description in the first load.
// You can change it to something else if you don't like my naming.
details: String,
category: String,
location: String,
// These two will be important later to help us make sure the job isn't stale
listingDate: String,
dateCrawled: Date,
//
salary: String,
url: String,
// Maybe you might want to do some analysis later - so we capture a ton of keywords
// then when we filter we get only the tags we want.
keywords: {
type: [String],
default: [],
},
});
// later on we will call this and assign its properties
export const Job = mongoose.model("Job", jobSchema);
Ok, now for the sanity check we try and write to the db using our model.
We already know we can get data, so let's tack the writing at the end of the script where we left off.
Alright, so we create the insert function and connect to the db with some logging for when things go pear-shaped or we are successful.
async function insertJob(jobPost) {
// connect to the mongodb
mongoose
.connect(mongoUrl, {
useNewUrlParser: true,
})
.then(() => {
console.log("Successfully connected to MongoDB.");
})
.catch((err) => {
console.log("Could not connect to MongoDB.");
process.exit();
});
// create a new job object and populate it with the job data from the jobPost object
const job = new Job({
title: jobPost.title,
company: jobPost.company,
details: jobPost.details,
category: jobPost.category,
location: jobPost.location,
listingDate: jobPost.listingDate,
dateCrawled: jobPost.dateScraped,
salary: jobPost.salary,
url: jobPost.url,
keywords: jobPost.keywords,
});
// save the job
job
.save(job)
.then((data) => {
console.log("Job saved successfully.");
})
.catch((err) => {
console.log("Could not save job.");
});
// close the connection to the database
mongoose.connection.close();
}
Now your index.js file should look like this
import puppeteer from "puppeteer"; // Importing the Puppeteer library for web scraping
import constants, { KEYWORDS } from "./utils/constants.js"; // Importing constants and keywords from the constants module
import mongoose from "mongoose"; // Importing the Mongoose library for MongoDB
import dotenv from "dotenv";
import { Job } from "./models/Job.js"; // Importing the Job model from the models module
dotenv.config(); // Configure dotenv to load the .env file
const mongoUrl = process.env.MONGO_URI; // Setting the MongoDB connection URL from the environment variable we set in the .env file
const jobTitle = "junior web developer"; // Setting the job title to search for.
const jobLocation = "Work from home"; // Setting the job location to search for
const searchUrl = constants.SEEK_URL + jobTitle + "-jobs?where=" + jobLocation; // Constructing the search URL
export default async function runJobScrape() {
const browser = await puppeteer.launch({
headless: false, // Launch Puppeteer in non-headless mode (visible browser window)
args: ["--no-sandbox"], // Additional arguments for Puppeteer
});
const page = await browser.newPage(); // Create a new page in the browser
await page.goto(constants.SEEK_URL); // Navigate the page to the SEEK website URL
await page.click(constants.KEYWORDS); // Click on the search input field for keywords
await page.keyboard.type(jobTitle); // Type the job title into the search input field
await page.click(constants.LOCATION); // Click on the search input field for location
await page.keyboard.type(jobLocation); // Type the job location into the search input field
await page.click(constants.SEARCH); // Click the search button
await new Promise((r) => setTimeout(r, 2000)); // Wait for 2 seconds (delay)
// await page.screenshot({ path: "./src/screenshots/search.png" });
// Take a screenshot of the search results page (optional)
let numPages = await getNumPages(page); // Get the total number of pages in the search results
console.log("getNumPages => total: ", numPages);
const jobList = []; // Create an empty array to store job information when we loop through the search results pages
for (let h = 1; h <= numPages; h++) {
let pageUrl = searchUrl + "&page=" + h; // Construct the URL for the current page of search results
await page.goto(pageUrl); // Navigate the page to the current search results page
console.log(`Page ${h}`); // log the current page number to console for visibility
// Find all the job elements on the page
const jobElements = await page.$$(
"div._1wkzzau0.szurmz0.szurmzb div._1wkzzau0.a1msqi7e"
);
for (const element of jobElements) {
const jobTitleElement = await element.$('a[data-automation="jobTitle"]'); // Find the job title element
const jobUrl = await page.evaluate((el) => el.href, jobTitleElement); // Extract the job URL from the job title element
// Extract the job title from the element
const jobTitle = await element.$eval(
'a[data-automation="jobTitle"]',
(el) => el.textContent
);
// Extract the job company from the element
const jobCompany = await element.$eval(
'a[data-automation="jobCompany"]',
(el) => el.textContent
);
// Extract the job details from the element
const jobDetails = await element.$eval(
'span[data-automation="jobShortDescription"]',
(el) => el.textContent
);
// Extract the job category from the element
const jobCategory = await element.$eval(
'a[data-automation="jobSubClassification"]',
(el) => el.textContent
);
// Extract the job location from the element
const jobLocation = await element.$eval(
'a[data-automation="jobLocation"]',
(el) => el.textContent
);
// Extract the job listing date from the element
const jobListingDate = await element.$eval(
'span[data-automation="jobListingDate"]',
(el) => el.textContent
);
// Now we check if the job details contain any of the keywords that we set out in utils/constants.js
// Ive done this as an exmaple to show when you store the jobs in the database, you can use the keywords to filter the jobs
// or use the keywords for other data related uses/analysis.
const jobDetailsHasKeywords = KEYWORDS.filter((keyword) =>
jobDetails.toLowerCase().includes(keyword.toLowerCase())
);
// the job salary is not always available, so we need to check if it exists before we try to extract it
let jobSalary = "";
try {
jobSalary = await element.$eval(
'span[data-automation="jobSalary"]',
(el) => el.textContent
);
} catch (error) {
// return an empty string if no salary is found for the job, we don't want to throw an error
jobSalary = "";
}
const job = {
title: jobTitle || "",
company: jobCompany || "",
details: jobDetails || "",
category: jobCategory || "",
location: jobLocation || "",
listingDate: jobListingDate || "",
salary: jobSalary || "",
dateScraped: new Date(),
url: jobUrl || "",
keywords: jobDetailsHasKeywords || [],
};
// verify the job object has been created correctly inside the loop
// console.log("Job elements loop => Job", job);
jobList.push(job);
}
}
// at this point we should have a jobList array full of data so now we insert the jobs into the database
for (const job of jobList) {
await insertJob(job);
// console.log("jobList loop => This is the current job:", job);
}
await browser.close();
}
// borrowed from https://github.com/ongsterr/job-scrape/blob/master/src/job-scrape.js
async function getNumPages(page) {
// Get the selector for the job count element from the constants
const jobCount = constants.JOBS_NUM;
// Use the page's evaluate function to run the following code in the browser context
let pageCount = await page.evaluate((sel) => {
let jobs = parseInt(document.querySelector(sel).innerText); // Get the inner text of the job count element and convert it to an integer
let pages = Math.ceil(jobs / 20); // Calculate the number of pages based on the total job count (assuming 20 jobs per page)
return pages; // Return the number of pages
}, jobCount);
return pageCount; // Return the total number of pages
}
async function insertJob(jobPost) {
// connect to the mongodb
mongoose
.connect(mongoUrl, {
useNewUrlParser: true,
})
.then(() => {
console.log("Successfully connected to MongoDB.");
})
.catch((err) => {
console.log("Could not connect to MongoDB.");
process.exit();
});
// create a new job object and populate it with the job data from the jobPost object
const job = new Job({
title: jobPost.title,
company: jobPost.company,
details: jobPost.details,
category: jobPost.category,
location: jobPost.location,
listingDate: jobPost.listingDate,
dateCrawled: jobPost.dateScraped,
salary: jobPost.salary,
url: jobPost.url,
keywords: jobPost.keywords,
});
// save the job and log it to the console for now
job
.save(job)
.then((data) => {
console.log("Job saved successfully.", data);
})
.catch((err) => {
console.log("Could not save job.");
});
}
runJobScrape();
npm index.js
Cool! Our logging inside the insert method tells us we are sending our job data over the wire and into a DB... omg I love this!! look at this data!!!
Job saved successfully. {
title: 'JavaScript Developer',
company: 'Rubix Solutions Pty Ltd',
details: 'JavaScript/Fullstack Engineers needed for growing tech company, working with high calibre team using: React, Vue, Angular',
category: 'Engineering - Software',
location: 'Sydney NSW',
listingDate: '6d ago',
dateCrawled: 2023-06-11T11:15:33.449Z,
salary: 'Yes',
url: 'https://www.seek.com.au/job/67928514?type=standout#sol=630063bb92b4d7573e046b2f6229526bd08bf499',
keywords: [ 'react', 'javascript', 'vue', 'java', 'angular', 'angular' ],
_id: new ObjectId("6485acdd5b7f606879b46fcc"),
__v: 0
}
Job saved successfully. {
title: 'Junior Technical Consultant (Sharepoint)',
company: 'The Recruitment Alternative',
details: 'HYBRID ROLE - REDFERN AREA - Two days in the office and three WFH. Work alongside and learn from a Snr Tech. Configure, troubleshoot, doc m/ment',
category: 'Consultants',
location: 'Sydney NSW',
listingDate: '20d ago',
dateCrawled: 2023-06-11T11:15:33.471Z,
salary: '',
url: 'https://www.seek.com.au/job/67640497?type=standard#sol=995538f32574cd9c61f26c272421f55226bad3b8',
keywords: [],
_id: new ObjectId("6485acdd5b7f606879b46fcd"),
__v: 0
}
Go to your DB dashboard and confirm
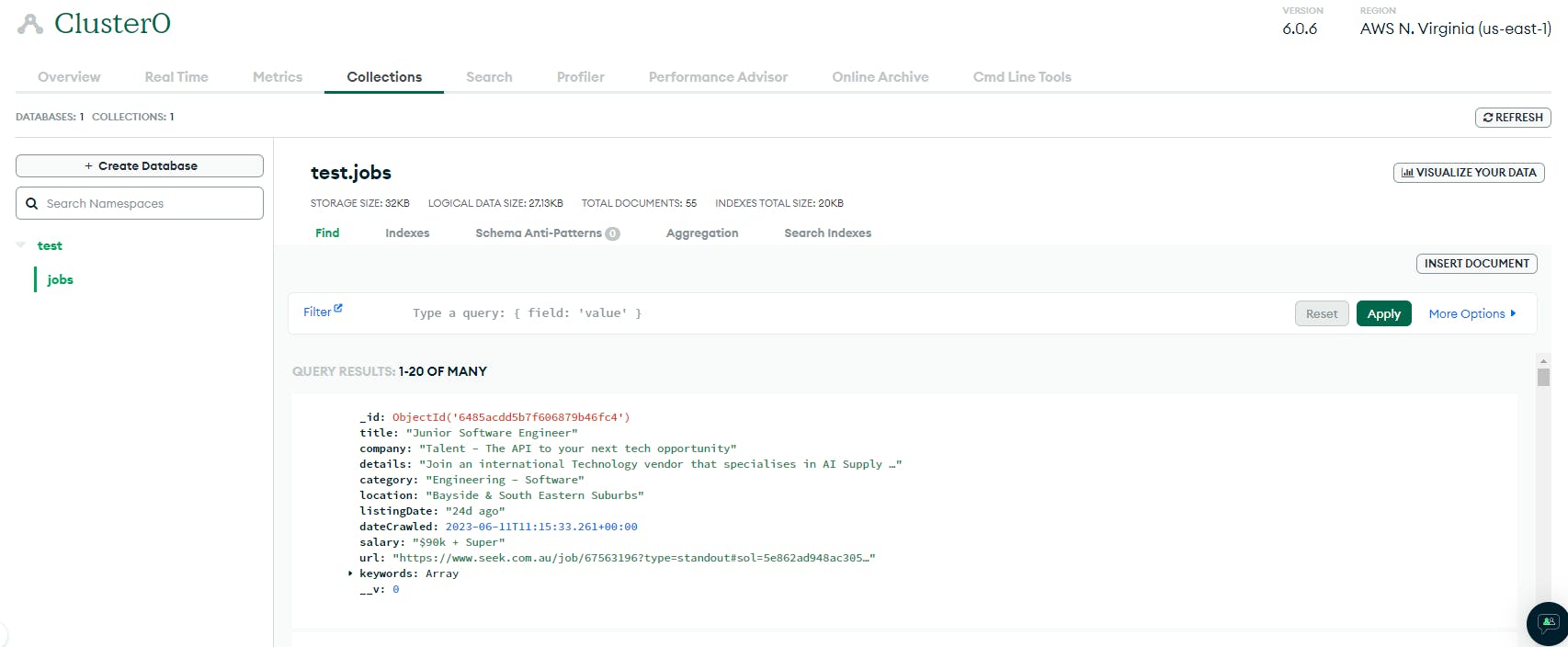

Alright, we're in business. Next stop let's query the DB and refine our results
Querying the Data
Noice,
Now we want to run a query and only return records in the DB with speiffic keywords. Or at least thats what im going to do - youcould get anything the data will allow really datee range, location, title etc.
Create a new file called Evaluate.js and copy this code in
import mongoose from "mongoose";
import dotenv from "dotenv";
import { Job } from "./models/job.js";
dotenv.config();
const mongoUrl = process.env.MONGO_URI;
const keywords = [
"Junior",
"Graduate/Junior",
"Graduate",
"React",
"Javascript",
"angular",
"Vue",
".net",
"sql",
"node",
"typescript",
"remote",
"work from home",
];
export const evaluate = async () => {
const jobOutput = [];
try {
await mongoose.connect(mongoUrl, {
useNewUrlParser: true,
});
const jobs = await Job.find({
title: {
// adjust your title keywords here
$regex: "Junior|Graduate/Junior|Graduate|React|Javascript|Vue|.NET",
$options: "i", // case insensitive
},
keywords: {
$in: keywords,
},
});
// now for each job we need to work out if it is still valid
for (const job of jobs) {
const dateCrawled = job.dateCrawled;
//listingDate: '29d ago', need to removed the d and ago
const listingDate = job.listingDate.replace("d ago", "");
const currentDate = new Date();
// total milliseconds / milliseconds in a day
const daysElapsed = Math.floor(
(currentDate - dateCrawled) / (24 * 60 * 60 * 1000)
);
const updatedListingDate = listingDate + daysElapsed;
if (updatedListingDate > 30) {
// Skip the job as it's been more than 30 days since the dateCrawled so the ad won;t exist anymore on seek
} else {
// Process the job
jobOutput.push(job);
}
}
console.log("Jobs from database", jobs);
return jobOutput;
} catch (error) {
console.log("Could not connect to MongoDB:", error);
process.exit(1);
}
};
You can see I've added a new keyword array for the actual keywords I want in my jobs and some logging to conform we are working well.
Go to your index.js file and add the evaluate function below which we call the runJobScrape(). You can comment on the scrape out for now because we have data already.
// runJobScrape();
evaluate();
run your project again and Cool! we get back a smaller list with word matching. Much much better than doom scrolling through the list of garbage seek usually serves up.

Email yourself the results

Alriiight. Now we have a curated, relevant list of jobs let's send it to ourselves via the interwebs.
Create a new file called email.js
import nodemailer from "nodemailer";
export const sendEmail = async (jobs) => {
// Create a nodemailer transporter
const transporter = nodemailer.createTransport({
host: "smtp.office365.com", // you will need to change this to the relevant service
port: 587,
secure: false,
auth: {
user: "somedude@outlook.com", // Replace with your email address
pass: "password123", // Replace with your password
},
});
try {
// Compose the email message and create some nice styling
const message = {
from: "somedude@outlook.com", // Sender email address
to: "somedude@outlook.com", // Recipient email address
subject: "New Job Opportunities",
html: `<html>
<head>
<style>
.job-card {
border: 1px solid #ccc;
padding: 10px;
margin-bottom: 20px;
}
.job-title {
color: #333;
margin-bottom: 10px;
}
.job-details {
margin-bottom: 10px;
}
.job-link {
color: blue;
text-decoration: underline;
}
.job-keywords {
margin-top: 10px;
}
</style>
</head>
<body>
${jobs
.map(
(job) => `
<div class="job-card">
<h2 class="job-title">${job.title}</h2>
<p><strong>Company:</strong> ${job.company}</p>
<p><strong>Location:</strong> ${job.location}</p>
<p class="job-details"><strong>Job Description:</strong></p>
<p>${job.details}</p>
<p><strong>Link:</strong> <a class="job-link" href="${job.url}">${
job.url
}</a></p>
<p class="job-keywords"><strong>Keywords:</strong> ${job.keywords.join(
", "
)}</p>
</div>
`
)
.join("")}
</body>
</html>`,
};
// Send the email
const info = await transporter.sendMail(message);
console.log("Email sent:", info.messageId);
} catch (error) {
// log us back the errors if there are any
console.log("Error sending email:", error);
}
};
export default sendEmail;
Ok update the relevant fields add the function tho the index.js and run it
and Boom!

Now, I can see there is a job for a senior in there which annoys me - our logic isn't good so go ahead and tighten up your rules as required.
One easy way to do this is to match the text using .includes() - it isn't hugely robust but I think it's unlikely that the job add text will change in 30 days so it should be ok.
import mongoose from "mongoose";
import dotenv from "dotenv";
import { Job } from "./models/job.js";
dotenv.config();
const mongoUrl = process.env.MONGO_URI;
const keywords = [
"Junior",
"Graduate/Junior",
"Graduate",
"React",
"Javascript",
"angular",
"Vue",
".net",
"sql",
"node",
"typescript",
"remote",
"work from home",
];
export const evaluate = async () => {
const jobOutput = [];
try {
await mongoose.connect(mongoUrl, {
useNewUrlParser: true,
});
const jobs = await Job.find({
title: {
$regex: "(Junior|Graduate/Junior|Graduate|React|Javascript|Vue|.NET)",
$options: "i", // case insensitive
},
keywords: {
$in: keywords,
},
});
// now for each job we need to work out if it is still valid
for (const job of jobs) {
const dateCrawled = job.dateCrawled;
const listingDate = job.listingDate.replace("d ago", "");
const currentDate = new Date();
const daysElapsed = Math.floor(
(currentDate - dateCrawled) / (24 * 60 * 60 * 1000)
);
const updatedListingDate = parseInt(listingDate) + daysElapsed;
if (updatedListingDate > 30) {
// Skip the job as it's been more than 30 days since the dateCrawled, and the ad won't exist anymore on Seek
continue;
}
// Tighten up the rules for job titles
const jobTitle = job.title.toLowerCase();
if (
!jobTitle.includes("senior") &&
!jobTitle.includes("lead") &&
!jobTitle.includes("manager")
) {
// Process the job
jobOutput.push(job);
}
}
console.log("Jobs from database", jobs);
return jobOutput;
} catch (error) {
console.log("Could not connect to MongoDB:", error);
process.exit(1);
}
};
Awesome, now the senior/lead jobs are being eliminated from the email.
One last thing - when we run the scraper - we don't want to keep loading the same jobs over and over again into the database.
So let's update the insert function to check if the job details match any other record. Again not foolproof but good enough for now. Also instead of looping over each job and inserting them one by one - let's bulk-check for matching details and discard the ones we don't want to enter.
async function insertJobs(jobPosts) {
try {
// Connect to the MongoDB
await mongoose.connect(mongoUrl, {
useNewUrlParser: true,
});
console.log("Successfully connected to MongoDB.");
// Get the list of existing job details in the database
const existingJobDetails = await Job.distinct("details");
// Filter out the existing jobs from the jobPosts array
const newJobs = jobPosts.filter(
(jobPost) => !existingJobDetails.includes(jobPost.details)
);
console.log(`Total jobs: ${jobPosts.length}`);
console.log(`Existing jobs: ${existingJobDetails.length}`);
console.log(`New jobs: ${newJobs.length}`);
// Process the new jobs
for (const jobPost of newJobs) {
const job = new Job({
title: jobPost.title,
company: jobPost.company,
details: jobPost.details,
category: jobPost.category,
location: jobPost.location,
listingDate: jobPost.listingDate,
dateCrawled: jobPost.dateScraped,
salary: jobPost.salary,
url: jobPost.url,
keywords: jobPost.keywords,
});
// Save the job
const savedJob = await job.save();
console.log("Job saved successfully:", savedJob);
}
} catch (error) {
console.log("Could not save jobs:", error);
} finally {
// Close the database connection
mongoose.connection.close();
}
}
then update your index.js to look like this
import puppeteer from "puppeteer"; // Importing the Puppeteer library for web scraping
import constants, { KEYWORDS } from "./utils/constants.js"; // Importing constants and keywords from the constants module
import mongoose from "mongoose"; // Importing the Mongoose library for MongoDB
import dotenv from "dotenv";
import { Job } from "./models/job.js"; // Importing the Job model from the models module
import { evaluate } from "./evaluate.js";
import { sendEmail } from "./email.js";
dotenv.config(); // Configure dotenv to load the .env file
const mongoUrl = process.env.MONGO_URI; // Setting the MongoDB connection URL from the environment variable we set in the .env file
const jobTitle = "junior web developer"; // Setting the job title to search for.
const jobLocation = "Work from home"; // Setting the job location to search for
const searchUrl = constants.SEEK_URL + jobTitle + "-jobs?where=" + jobLocation; // Constructing the search URL
export default async function runJobScrape() {
const browser = await puppeteer.launch({
headless: false, // Launch Puppeteer in non-headless mode (visible browser window)
args: ["--no-sandbox"], // Additional arguments for Puppeteer
});
const page = await browser.newPage(); // Create a new page in the browser
await page.goto(constants.SEEK_URL); // Navigate the page to the SEEK website URL
await page.click(constants.KEYWORDS); // Click on the search input field for keywords
await page.keyboard.type(jobTitle); // Type the job title into the search input field
await page.click(constants.LOCATION); // Click on the search input field for location
await page.keyboard.type(jobLocation); // Type the job location into the search input field
await page.click(constants.SEARCH); // Click the search button
await new Promise((r) => setTimeout(r, 2000)); // Wait for 2 seconds (delay)
// await page.screenshot({ path: "./src/screenshots/search.png" });
// Take a screenshot of the search results page (optional)
let numPages = await getNumPages(page); // Get the total number of pages in the search results
console.log("getNumPages => total: ", numPages);
const jobList = []; // Create an empty array to store job information when we loop through the search results pages
for (let h = 1; h <= numPages; h++) {
let pageUrl = searchUrl + "&page=" + h; // Construct the URL for the current page of search results
await page.goto(pageUrl); // Navigate the page to the current search results page
console.log(`Page ${h}`); // log the current page number to console for visibility
// Find all the job elements on the page
const jobElements = await page.$$(
"div._1wkzzau0.szurmz0.szurmzb div._1wkzzau0.a1msqi7e"
);
for (const element of jobElements) {
const jobTitleElement = await element.$('a[data-automation="jobTitle"]'); // Find the job title element
const jobUrl = await page.evaluate((el) => el.href, jobTitleElement); // Extract the job URL from the job title element
// Extract the job title from the element
const jobTitle = await element.$eval(
'a[data-automation="jobTitle"]',
(el) => el.textContent
);
// Extract the job company from the element
const jobCompany = await element.$eval(
'a[data-automation="jobCompany"]',
(el) => el.textContent
);
// Extract the job details from the element
const jobDetails = await element.$eval(
'span[data-automation="jobShortDescription"]',
(el) => el.textContent
);
// Extract the job category from the element
const jobCategory = await element.$eval(
'a[data-automation="jobSubClassification"]',
(el) => el.textContent
);
// Extract the job location from the element
const jobLocation = await element.$eval(
'a[data-automation="jobLocation"]',
(el) => el.textContent
);
// Extract the job listing date from the element
const jobListingDate = await element.$eval(
'span[data-automation="jobListingDate"]',
(el) => el.textContent
);
// Now we check if the job details contain any of the keywords that we set out in utils/constants.js
// Ive done this as an exmaple to show when you store the jobs in the database, you can use the keywords to filter the jobs
// or use the keywords for other data related uses/analysis.
const jobDetailsHasKeywords = KEYWORDS.filter((keyword) =>
jobDetails.toLowerCase().includes(keyword.toLowerCase())
);
// the job salary is not always available, so we need to check if it exists before we try to extract it
let jobSalary = "";
try {
jobSalary = await element.$eval(
'span[data-automation="jobSalary"]',
(el) => el.textContent
);
} catch (error) {
// return an empty string if no salary is found for the job, we don't want to throw an error
jobSalary = "";
}
const job = {
title: jobTitle || "",
company: jobCompany || "",
details: jobDetails || "",
category: jobCategory || "",
location: jobLocation || "",
listingDate: jobListingDate || "",
salary: jobSalary || "",
dateScraped: new Date(),
url: jobUrl || "",
keywords: jobDetailsHasKeywords || [],
};
// verify the job object has been created correctly inside the loop
// console.log("Job elements loop => Job", job);
jobList.push(job);
}
}
await insertJobs(jobList);
await browser.close();
}
// borrowed from https://github.com/ongsterr/job-scrape/blob/master/src/job-scrape.js
async function getNumPages(page) {
// Get the selector for the job count element from the constants
const jobCount = constants.JOBS_NUM;
// Use the page's evaluate function to run the following code in the browser context
let pageCount = await page.evaluate((sel) => {
let jobs = parseInt(document.querySelector(sel).innerText); // Get the inner text of the job count element and convert it to an integer
let pages = Math.ceil(jobs / 20); // Calculate the number of pages based on the total job count (assuming 20 jobs per page)
return pages; // Return the number of pages
}, jobCount);
return pageCount; // Return the total number of pages
}
async function insertJobs(jobPosts) {
try {
// Connect to the MongoDB
await mongoose.connect(mongoUrl, {
useNewUrlParser: true,
});
console.log("Successfully connected to MongoDB.");
// Get the list of existing job details in the database
const existingJobDetails = await Job.distinct("details");
// Filter out the existing jobs from the jobPosts array
const newJobs = jobPosts.filter(
(jobPost) => !existingJobDetails.includes(jobPost.details)
);
console.log(`Total jobs: ${jobPosts.length}`);
console.log(`Existing jobs: ${existingJobDetails.length}`);
console.log(`New jobs: ${newJobs.length}`);
// Process the new jobs
for (const jobPost of newJobs) {
const job = new Job({
title: jobPost.title,
company: jobPost.company,
details: jobPost.details,
category: jobPost.category,
location: jobPost.location,
listingDate: jobPost.listingDate,
dateCrawled: jobPost.dateScraped,
salary: jobPost.salary,
url: jobPost.url,
keywords: jobPost.keywords,
});
// Save the job
const savedJob = await job.save();
console.log("Job saved successfully:", savedJob);
}
} catch (error) {
console.log("Could not save jobs:", error);
} finally {
// Close the database connection
mongoose.connection.close();
}
}
await runJobScrape();
const evaluationResults = await evaluate();
await sendEmail(evaluationResults);
Nice! That's it for Part 2 of our job-search helper project, we have accomplished significant milestones. We successfully created a database, stored job records, implemented some querying/selection to refine our results, and tightened up our logic to exclude unwanted job posts. Additionally, we integrated the email functionality and made necessary code refactorings for better organization and readability.
Join me for the final part where we harness the power of Langchain.js and OpenAi to make our output more interesting and valuable to us.
Happy Coding!