




Database background
Common Types of databases:
The most common types of databases for web development would be Relational and NoSQL
Relational: The idea of a relational database was developed in 1970 by E.F. Codd at IBM in his research paper “A Relational Model of Data for Large Shared Data Banks.”
A common misnomer is that they are called "relational" because the tables relate to one another but each table is a relation with columns or attributes and rows (also called a record).
Relational databases enforce data integrity using keys and references from one table to another - this data integrity is often a very valuable commodity and hence why the RDB is so widely used.
There is a drawback though - when DB's become very large (millions of rows) and complicated - getting information from tables with so many joins can not only be complicated in terms of queries but may become a very slow process when retrieving the data.
 reference: dataedo.com
reference: dataedo.com
When trying to reduce your compute spend on your AWS RDS instance this is something that you must consider as long queries will lead to increased compute time which will definitely annoy your users.
In my instance, I’m using a relational database using MS-SQL which is ACID compliant the ACID acronym stands for
Atomicity: "All changes to data are performed as if they are a single operation. That is, all the changes are performed, or none of them are."
Consistency: "Data is in a consistent state when a transaction starts and when it ends."
Isolation: "The intermediate state of a transaction is invisible to other transactions. As a result, transactions that run concurrently appear to be serialized. For example, in an application that transfers funds from one account to another, the isolation property ensures that another transaction sees the transferred funds in one account or the other, but not in both, nor in neither."
Durability: "After a transaction successfully completes, changes to data persist and are not undone, even in the event of a system failure. For example, in an application that transfers funds from one account to another, the durability property ensures that the changes made to each account will not be reversed."
some NoSQL DB's are ACID compliant but in general, because they don’t have the same rules that enforce referential integrity they use the BASE model instead
Basically Available:: "Guarantees the availability of the data . There will be a response to any request (can be failure too).
Soft state:: "The state of the system could change over time."
Eventual consistency: " The system will eventually become consistent once it stops receiving input."
NoSQL:
In the 2000's as the cost of storage was decreasing and the volumes of data was increasing - companies like Google and Facebook were starting to get a TON of data that was unstructured - which does not suit realtional db's.
enter the NoSQL, basically storing data in JSON objects format
You lose the data integrity as the ACID principles don’t apply but you get eventual consistency.
Without a schema, you can add fields as required and store pretty much any data without having to come up with a complex schema first.
NoSQL databases also support scaling out rather than up, so scaling up would mean getting bigger machines, bigger processors and more memory rather than scaling out which mean using lots and lots of machines together to achieve the same effect.
The side effect of this is increased resilience - if one machine in the cluster drops out the others can survive and keep the DB up and running until the other machines comes back online or is replaced.
example of a NoSQL db object:
 source: aws.amazon.com/nosql/document
source: aws.amazon.com/nosql/document
Graph:
According to AWS "A graph database’s purpose is to make it easy to build and run applications that work with highly connected datasets. Typical use cases for a graph database include social networking, recommendation engines, fraud detection, and knowledge graphs."
I haven't used a graph database before but they look really really interesting - the idea being that you can have as many relationships as you want without sacrificing query speed. They are NoSQL
I will add graph databases as an option in the DB table, I’m making a note to myself to research some good projects that would suit a graph db.
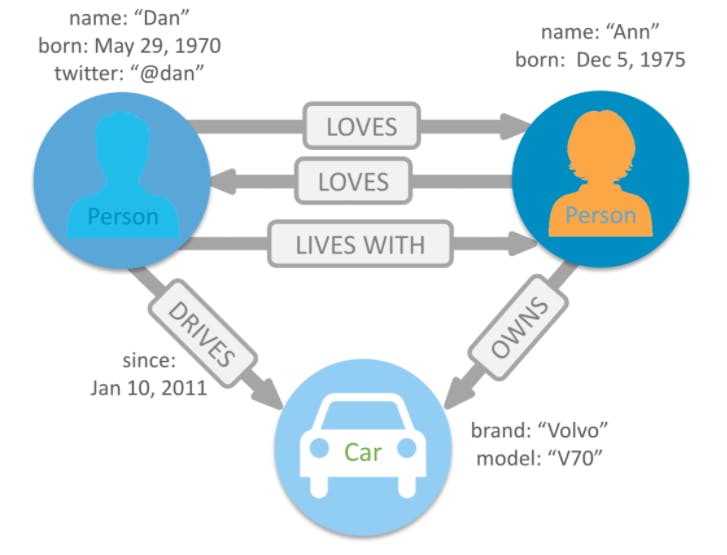 source: neo4j.com/developer/graph-database/#why-gra..
source: neo4j.com/developer/graph-database/#why-gra..
Relationships:
I don’t want to go in to deep here because there is a ton of information around with this stuff. O’Reilly has a ton of books, LinkedIn Learning, FreeCodeCamp on youtube, DataCamp just to name a few - but all I’m saying is I don’t need to lay it all out here.
With that said I just wanted to touch on the relationships and the question I ask myself when trying to determine whether a relationship is one of the following
"Can a single instance of this entity be associated with one or many instances of the other entity"
One to many:
In my project each project can only have a single type of deployment - but a single type of deployment can be associated with many projects therefore the relationship is one to many.
Many to Many:
for example, in my schema I want each project to have multiple categories - so when I ask the above question - a project can have many categories and a single category can be associated with many projects.
Schema:
Now that we know a bit more about the DB, we are going to write the ERD or (Entity Relationship Diagram)
I want to visualise the relationship of my database as connected boxes using special lines to show which way the relationships go and what type of entity each table is (strong or weak?)
in the many to many example above we should not have a many to many relationship - so to implement this we use an expansion table - it has lots of other names as well like junction table, intersection entity etc.
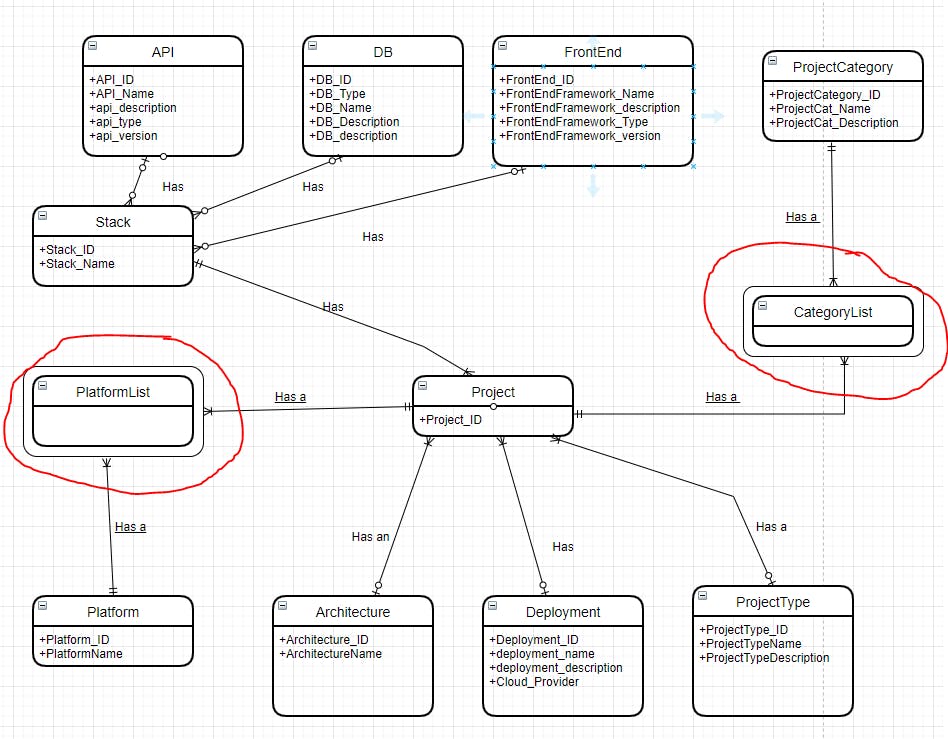
Types of ERD notation:
I use draw.io for my modelling, it's free and they have improved it a lot over the last couple of years. As far as I am aware there are two types of ERD notation - Chens and Crows Foot. I learned the crow's foot notation - so I’m going to use that although I have noticed during my studies that a LOT of the information was laid out using the Chen notation.
Code:
So now that i have my ERD its time to bust out the 'ol IDE and lay down some code
-- the project category table is a table that holds the different categories that a project can have e.g medical, ecommerce etc ---
CREATE TABLE PROJECT_CATEGORY(
PROJECT_CATEGORY_ID INT,
PROJECT_CATEGORY_NAME NVARCHAR(100),
PROJECT_CATEGORY_DESCRIPTION NVARCHAR(500)
PRIMARY KEY(PROJECT_CATEGORY_ID)
);
-- project type table is a table that holds the different types of projects e.g web, mobile, desktop etc ---
CREATE TABLE PROJECT_TYPE(
PROJECT_TYPE_ID INT,
PROJECT_TYPE_NAME NVARCHAR(100),
PROJECT_TYPE_DESCRIPTION NVARCHAR(500)
PRIMARY KEY (PROJECT_TYPE_ID)
)
-- deployment table is a table that holds the different types of deployments e.g cloud, on premise etc ---
CREATE TABLE DEPLOYMENT (
DEPLOYMENT_ID INT,
DEPLOYMENT_NAME NVARCHAR(100),
DEPLOYMENT_DESCRIPTION NVARCHAR(500),
CLOUD_PROVIDER NVARCHAR(20),
PRIMARY KEY (DEPLOYMENT_ID)
)
-- architecture table is a table that holds the different types of architectures e.g onion, ddd, monolith, microservices etc ---
CREATE TABLE ARCHITECTURE (
ARCHITECTURE_ID INT,
ARCHITECTURE_NAME NVARCHAR(100)
PRIMARY KEY (ARCHITECTURE_ID)
)
-- platform table is a table that holds the different types of platforms e.g windows, linux, mac --
CREATE TABLE [PLATFORM] (
PLATFORM_ID INT,
PLATFORM_NAME NVARCHAR(100)
PRIMARY KEY (PLATFORM_ID)
);
-- stack table is a table that holds the different types of stacks e.g LAMP, MEAN, MEAN-PHP, MEAN-JS etc ---
CREATE TABLE STACK (
STACK_ID INT,
STACK_NAME NVARCHAR(100)
PRIMARY KEY (STACK_ID)
);
-- the API table is a table that holds the different types of API languages - e.g C#, Node.js, Java etc ---
CREATE TABLE API (
API_ID INT,
API_NAME NVARCHAR(100),
API_DESCRIPTION NVARCHAR(500),
API_TYPE NVARCHAR(20),
API_VERSION NVARCHAR(20),
PRIMARY KEY (API_ID)
);
-- DB table is a table that holds the different types of DB languages - e.g SQL, NoSQL etc ---
CREATE TABLE DB (
[DB_ID] INT,
[DB_NAME] NVARCHAR(100),
[DB_DESCRIPTION] NVARCHAR(500),
[DB_TYPE] NVARCHAR(20),
[DB_VERSION] NVARCHAR(20),
PRIMARY KEY ([DB_ID])
);
-- front end table is a table that holds the different types of front end languages - e.g HTML, Angular, React, Flask, Gatsby etc ---
CREATE TABLE FRONTEND (
FRONTEND_ID INT,
FRONTENDFRAMEWORK_NAME NVARCHAR(100),
FRONTENDFRAMEWORK_DESCRIPTION NVARCHAR(500),
FRONTENDFRAMEWORK_TYPE NVARCHAR(20),
FRONTENDFRAMEWORK_VERSION NVARCHAR(20)
PRIMARY KEY (FRONTEND_ID)
);
CREATE TABLE PROJECT(
PROJECT_ID INT, --- this needs o be auto incrementing ---
PROJECT_CATEGORY_ID INT, --- this needs to be a foreign key to the project category table
PROJECT_TYPE_ID INT, --- this needs to be a foreign key to the project type table
DEPLOYMENT_ID INT, --- this needs to be a foreign key to the deployment table
ARCHITECTURE_ID INT, --- this needs to be a foreign key to the architecture table
STACK_ID INT, --- this needs to be a foreign key to the stack table
PRIMARY KEY(PROJECT_ID), --- this needs to be a primary key
FOREIGN KEY(PROJECT_CATEGORY_ID) REFERENCES PROJECT_CATEGORY,
FOREIGN KEY(PROJECT_TYPE_ID) REFERENCES PROJECT_TYPE(PROJECT_TYPE_ID),
FOREIGN KEY(DEPLOYMENT_ID) REFERENCES DEPLOYMENT(DEPLOYMENT_ID),
FOREIGN KEY(ARCHITECTURE_ID) REFERENCES ARCHITECTURE(ARCHITECTURE_ID),
FOREIGN KEY(STACK_ID) REFERENCES STACK(STACK_ID)
);
-- the category list table is an expansion table for the project table given that the project should have mulitple categories ---
CREATE TABLE CATEGORY_LIST (
PROJECT_ID INT,
PROJECT_CATEGORY_ID INT
PRIMARY KEY(PROJECT_ID, PROJECT_CATEGORY_ID),
FOREIGN KEY (PROJECT_ID) REFERENCES PROJECT(PROJECT_ID),
FOREIGN KEY (PROJECT_CATEGORY_ID) REFERENCES PROJECT_CATEGORY(PROJECT_CATEGORY_ID)
)
-- platform list table is an expansion table that holds the different types of platforms e.g windows, linux, mac as coneciveably an application could be multi platform etc ---
CREATE TABLE PLATFORMLIST(
PLATFORM_ID INT,
PROJECT_ID INT,
FOREIGN KEY (PROJECT_ID) REFERENCES PROJECT(PROJECT_ID),
FOREIGN KEY (PLATFORM_ID) REFERENCES [PLATFORM](PLATFORM_ID)
)
Deployment:
For now im going to use SSMS for local deployment for development - a. because I love it 😂 and b. becuase i don't want to waste any of my precious cloud DB credit in dev mode.
Ok, so now we have the data models in place I need to create the data for the tables and get to work on defining the endpoints.
Once i have that I will us e the DB first method and scaffold EF in my .NET API.
Thanks for reading!
Ben
Sources:
pluralsight.com/blog/software-development/r..
mongodb.com/nosql-explained/nosql-vs-sql